tags: [‘思路’]
categories: ‘经验教程’
sticky: ‘9’
# 前言
学习逆向过程中的一些问题与其解决办法,当然还有大佬们文章内提到的,整理出来方便翻阅,持续更新。
1 | {% tip key %}当然大家有什么问题也可在下方评论,如有解决本文问题的方法还请不吝赐教,在此感谢鞠躬!{% endtip %} |
# 参考资料
# 资源工具
- CyberChef - 用于加密,编码,压缩和数据分析
- armconverter - ARM-HEX 转换器
- r0capture - 安卓应用层抓包通杀脚本
- ExAndroidNativeEmu - Python 工具 Unidbg 青春版功能有限
- findhash - IDA 脚本 可以检测出哈希算法
- ddddocr - Python 库 通用验证码识别库
# IDA
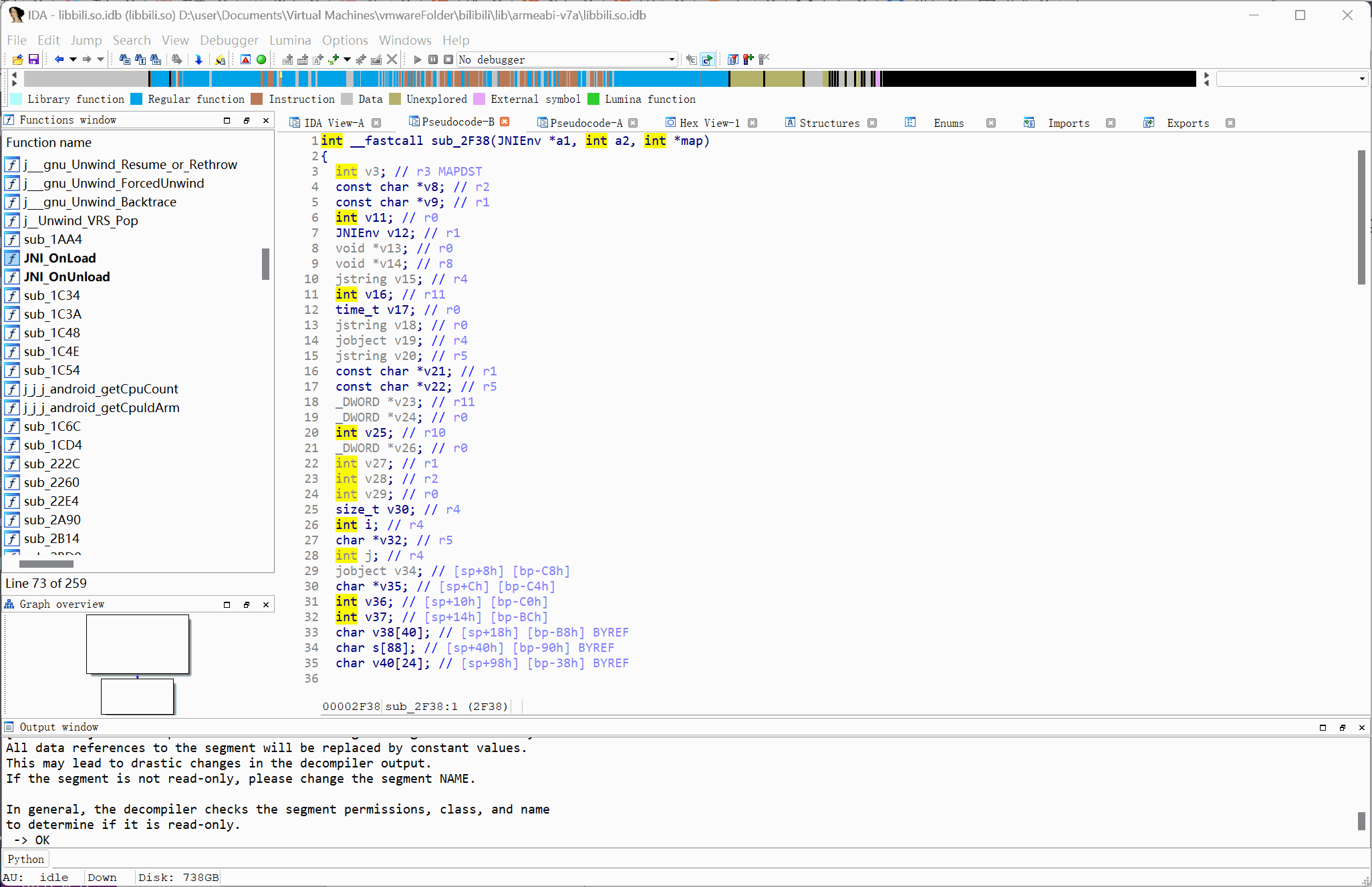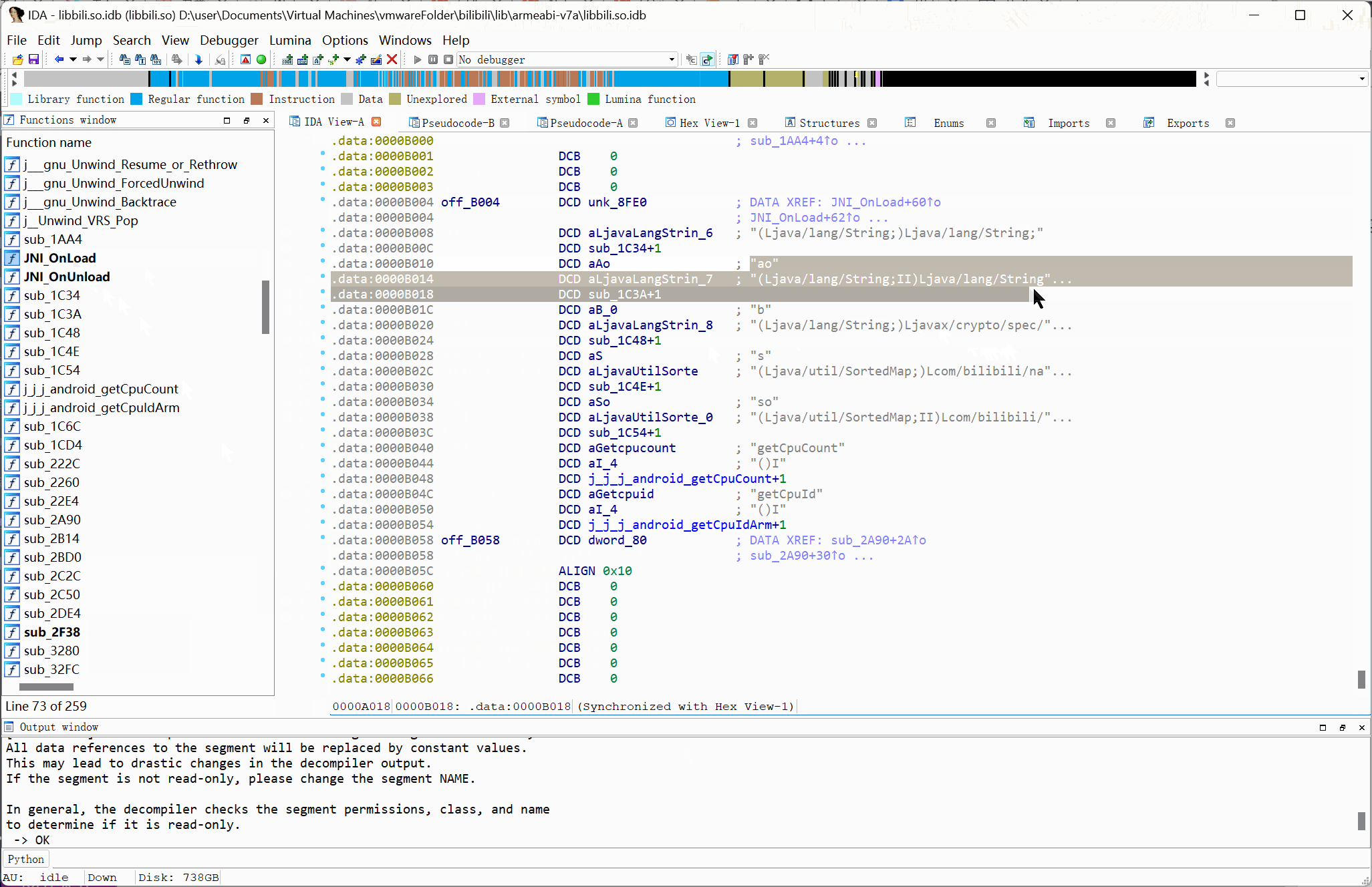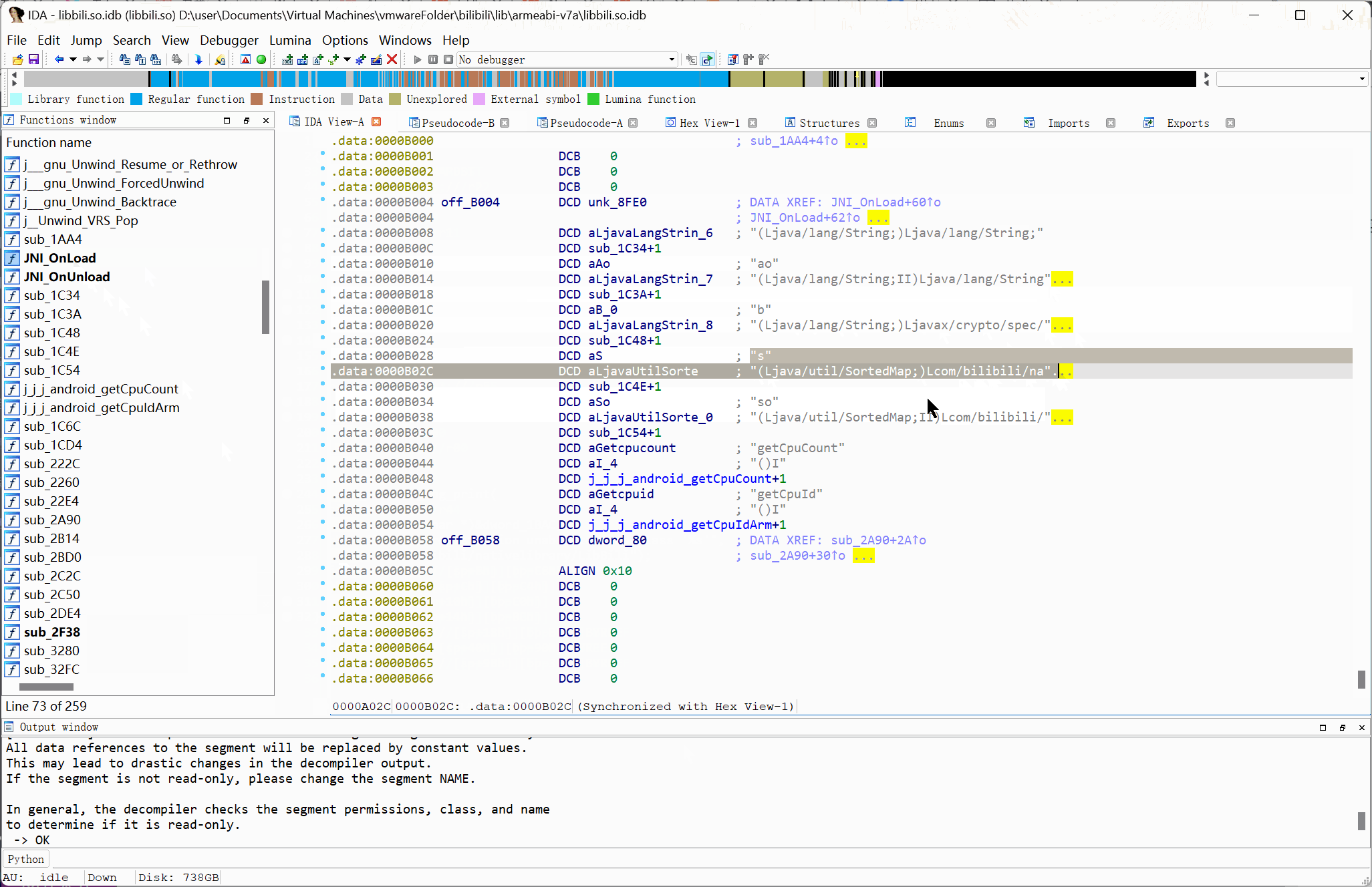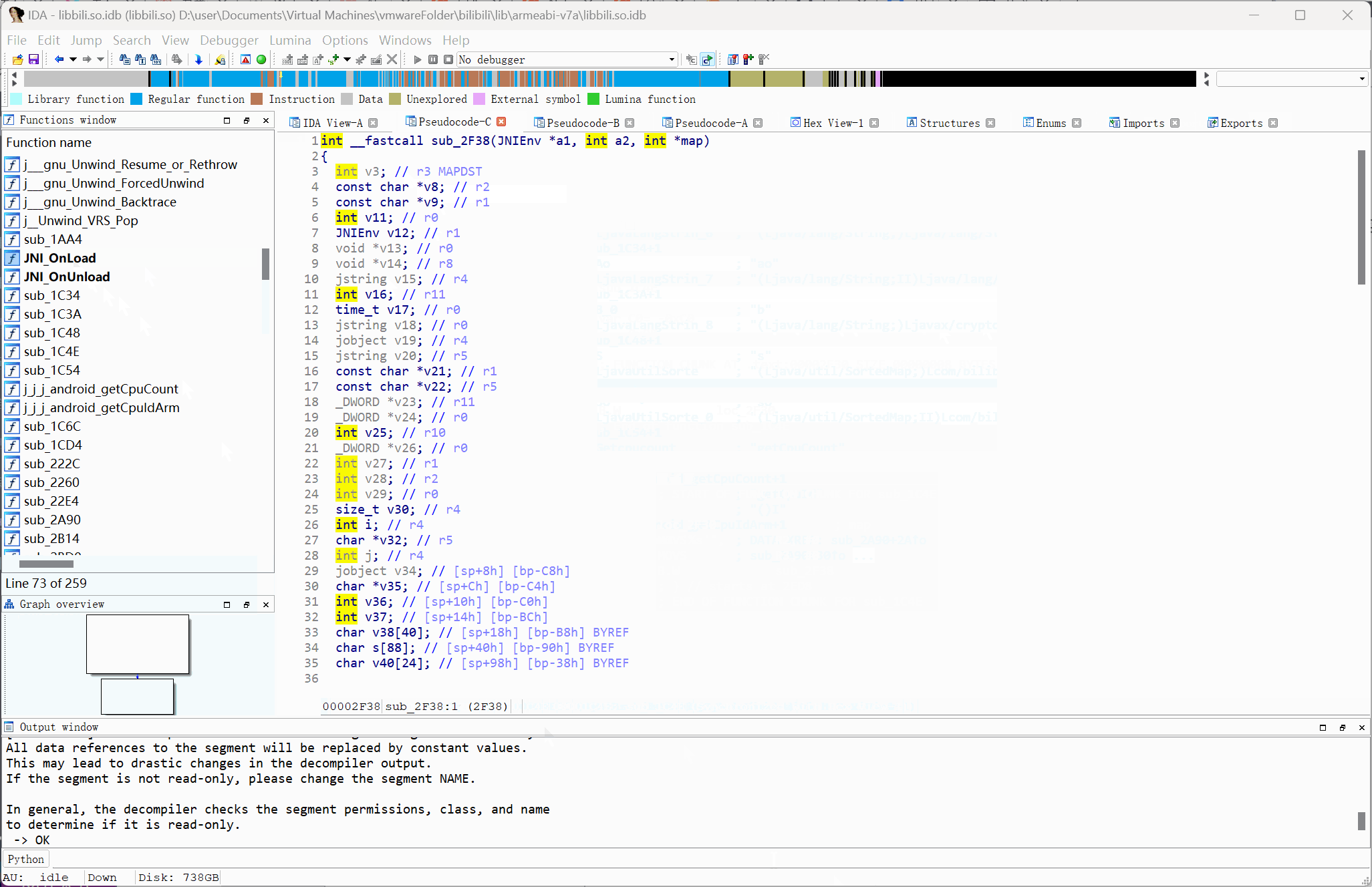
# 通过 JNI_OnLoad 定位 Native 函数
1 | {% tip info %}仅限没有经过混淆或加密处理的样本{% endtip %} |
# Python
# Python 能不能调用 so 文件的 Native 方法?
Python 也有类似 Unidbg 的工具 ExAndroidNativeEmu - Python 工具 Unidbg 青春版功能有限,但是仅限于对JAVA 层的交互极少,一旦涉及到 JNI 交互,则需要果断选择 Unidbg,在 Python 中补 JAVA 的逻辑,简直不是人该受的委屈。
# 密码学
# 加密算法大概率是开源或者魔改算法有没有快速验证的方法?
当在分析过程中有猜测或怀疑是某加密算法时可以使用类似 findhash - IDA 脚本 可以检测出哈希算法的脚本,此脚本可检测无论是否魔改常数的 hash 算法 MD5,SHA1、SHA2。
# 汇编指令
# ARM32 有 Thumb 和 ARM 两种指令模式如何确定?
最粗暴的方式就是试错法module.callFunction时不加 1会报错非法指令则表示是 Thumb 模式
第二个办法是从知识角度出发,ARM 模式指令总是 4 字节长度,Thumb 指令长度多数为 2 字节,少部分指令是 4 字节。
# Unidbg
# Unidbg 的 Jnionload 加载出的类是乱码?
so 做了字符串的混淆或加密,以此来对抗分析人员,但字符串总是要解密的,不然怎么用呢?这个解密一般发生在 Init array 节或者 JNI OnLoad 中,又或者是该字符串使用前的任何一个时机
# 对虚拟内存进行修改
Unidbg 提供了两种方法打 Patch,简单的需求可以调用 Unicorn 对虚拟内存进行修改,如下
1 | public void patchVerify(){ |
1 | {% tip warning %}需要注意的是,这儿地址可别+1了,Thumb的+1只在运行和Hook时需要考虑,打Patch可别想。{% endtip %} |
# 补环境怎么补补什么?
我们既可以根据报错提示,在 AbstractJni 对应的函数体内,依葫芦画瓢,case "xxx“。
也可以在我们的 zuiyou 类中补,因为 zuiyou 类继承了 AbstractJNI。
关于补法,有两种实践方法都很有道理
- 全部在用户类中补,防止项目迁移或者 Unidbg 更新带来什么问题,这样做代码的移植性比较好。
- 自定义 JAVA 方法在用户类中补,通用的方法在 AbstractJNI 中补,这样做的好处是,之后运行的项目如果调用通用方法,就不用做重复的修补工作。
# 如何主动调用一个 Native 函数
在 Frida 中可以使用 NativeFunction API 主动调用
1 | function call_65540(base_addr){ |
在 Unidbg 也是类似的,只不过换一下 API 罢了,让我们来看一下
1 | public void callMd5(){ |
需要注意,在 Unidbg 中,同样的功能有至少两种实现和写法 ——Unicorn 的原生方法以及 Unidbg 封装后的方法,在阅读别人代码时需要灵活变通。就好比 getR0long 和emulator.getBackend().reg_read(ArmConst.UC_ARM_REG_R0),它们都是获取寄存器 R0 的数值。
# JNItrace trace 我们在参数还没完全转换完的情况下,Unidbg 就退出了
这种情况下,可能的原因有很多,但可能性较大的是两个
- 上下文环境缺失
- 样本使用某种手段检测或反制了 Unidbg
先看一下是否是上下文的问题,假设是上下文缺失,通俗的讲就是在 SO 加载后到我们的 main 函数调用前的这段时间里,样本需要调用一些函数对 SO 进行初始化,而我们没有注意也没做这个事,这导致了 Unidbg 无法顺利运行。
# 抓包
# 对于服务器校验证书如何抓包?
安卓可以使用 r0capture - 安卓应用层抓包通杀脚本进行抓包分析。
# 验证码
# 遇到验证码验证怎么办?
可以使用 ddddocr - Python 库 通用验证码识别库进行识别,支持老版验证码,当前验证码支持部分滑块文字点选等。
# 解混淆 & 反编译对抗
# AI 如何赋能解混淆研究?
在代码混淆对抗中,如果要训练一个模型来识别 AST JSON 数据中的混淆特征,可以考虑使用以下几种算法:
- 机器学习算法:可以使用监督学习算法,如支持向量机(SVM)或随机森林,这些算法可以学习混淆代码和正常代码之间的模式差异。首先需要有一个标记好的特征数据集来训练模型,然后使用训练好的模型对新的代码样本进行分类和识别。
- 深度学习算法:特别是卷积神经网络(CNN)或循环神经网络(RNN),这些网络能够处理序列数据并识别复杂的模式。对于处理 AST 这种树状结构的数据,图神经网络(GNN)可能是一个更合适的选择,因为它们能够更好地处理图结构数据中的依赖关系。
- 自然语言处理算法:尽管 AST 不是自然语言,但可以使用 BERT 等预训练的语言模型来学习代码的语义表示,进而识别混淆模式。这些模型已经在自然语言处理领域显示出强大的能力,并且可以适应不同的语言和结构化数据。
- 基于规则的方法:可以设计一套规则系统来检测常见的混淆技术,如变量名和函数名的重命名、控制流的改变等。这种方法可能需要专业知识来定义混淆的特征和规则。
- AST 分析工具:可以使用现成的 AST 分析工具,如 Babel 或 Esprima,来解析和分析 JavaScript 代码。这些工具可以帮助识别代码中的模式和潜在的混淆技术,并可能结合机器学习算法来提高识别的准确性。
在选择算法时,需要考虑数据的规模、特征的复杂性以及所需的准确性。同时,混淆技术的不断进步也要求模型能够适应新的混淆手段。通过结合多种算法和工具,可以更有效地识别和对抗代码混淆。
云梯密码 VWzMDAwrm3s!6xx
本文采用 署名 - 非商业性使用 - 相同方式共享 4.0 国际 许可协议,转载请注明出处。




